 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomino: Decoupling Causal Modeling from Autoregressive Drafting in Speculative Decoding
May 28, 2026Speculative decoding accelerates LLM inference by drafting multiple tokens and verifying them in parallel with the target model. However, its practical speedup is constrained by the trade-off between draft quality and drafting cost: autoregressive drafters model causal dependencies among draft tokens but incur sequential overhead, while parallel drafters reduce drafting cost but weaken intra-block dependency modeling. In this paper, we propose Domino, a speculative decoding framework that decouples causal dependency modeling from expensive autoregressive draft execution. Domino first uses a parallel draft backbone to produce preliminary draft distributions for the entire block, and then applies a lightweight Domino head to refine them with prefix-dependent causal information. To stabilize teacher-forced causal encoding, we further introduce a base-anchored training curriculum that first strengthens the parallel backbone and then gradually shifts optimization toward the causally corrected final distribution. Experiments on Qwen3 models show that Domino achieves up to \(5.49\times\) end-to-end speedup under the Transformers backend and up to \(5.8\times\) throughput speedup under SGLang serving.
Share More, Search Less: Collaborative Parallel Thinking for Efficient Test-Time Scaling
May 26, 2026Test-Time Scaling (TTS) enhances the reasoning capabilities of large language models by allocating additional inference compute to explore the solution space. However, existing parallel TTS methods typically keep branches isolated during search: intermediate discoveries remain branch-private and cannot guide other branches in time. This information isolation causes substantial redundant exploration, as branches repeatedly rediscover information already found elsewhere and require more search steps to collect complete decision information needed to reach correct answers. To bridge this gap, we propose \textbf{Collaborative Parallel Thinking (CPT)}, a training-free inference framework that enables search-time information sharing across parallel branches. CPT extracts compact intermediate information from ongoing branches, maintains a deduplicated query-level information pool, and broadcasts pool entries through the input context, allowing each branch in subsequent search steps to reuse discoveries made by other branches rather than rediscover the same information. Empirically, experiments on HMMT and AIME benchmarks show that CPT establishes a stronger accuracy--latency Pareto frontier than strong baselines across rollout budgets and model scales, highlighting search-time collaboration as an effective direction for efficient parallel TTS.
Focused Forcing: Content-Aware Per-Frame KV Selection for Efficient Autoregressive Video Diffusion
May 18, 2026Recent advances in autoregressive video diffusion have enabled sequential and streaming video generation. However, long-horizon generation requires increasingly large KV caches, making efficient compression without sacrificing quality challenging. Existing methods mostly select historical frames based on attention scores, but their context decisions remain coarse. When multiple frames are generated in the same chunk, these methods often apply a shared history selection to the whole chunk, score historical frames solely by attention, and assign head-wise budgets either uniformly or by attention-pattern heuristics rather than explicit head-importance estimation. We show that frames within the same generated chunk can depend on distinct historical frames, that the same historical frame can receive different attention scores as its relative temporal distance to the current frames changes, and that masking different heads induces unequal generation degradation. Motivated by these findings, we propose \textbf{Focused Forcing}, a training-free KV selection method that focuses cached history along both generated-frame and head dimensions. For each generated frame, Focused Forcing preserves the most relevant and distinctive historical frames by combining attention scores with diversity scores of historical frames, while assigning larger budgets to heads with higher estimated importance. Across multiple autoregressive generation paradigms, Focused Forcing achieves up to $\textbf{1.48}\times$ end-to-end acceleration without training, while \textbf{improving visual quality and text alignment}. \textit{Our code will be released on GitHub.}
VISD: Enhancing Video Reasoning via Structured Self-Distillation
May 07, 2026Training VideoLLMs for complex reasoning remains challenging due to sparse sequence level rewards and the lack of fine grained credit assignment over long, temporally grounded reasoning trajectories. While reinforcement learning with verifiable rewards (RLVR) provides reliable supervision, it fails to capture token level contributions, leading to inefficient learning. Conversely, existing self distillation methods offer dense supervision but lack structure and diagnostic specificity, and often interact unstably with reinforcement learning. In this work, we propose VISD, a structured self distillation framework that introduces diagnostically meaningful privileged information for video reasoning. VISD employs a video aware judge model to decompose reasoning quality into multiple dimensions, including answer correctness, logical consistency, and spatio-temporal grounding, and uses this structured feedback to guide a teacher policy for token level supervision. To stably integrate dense supervision with RL, we introduce a direction magnitude decoupling mechanism, where rollout level advantages computed from rewards determine update direction, while structured privileged signals modulate token level update magnitudes. This design enables semantically aligned and fine grained credit assignment, improving both reasoning faithfulness and training efficiency. Additionally, VISD incorporates curriculum scheduling and EMA based teacher stabilization to support robust optimization over long video sequences. Experiments on diverse benchmarks show that VISD consistently outperforms strong baselines, improving answer accuracy and spatio temporal grounding quality. Notably, VISD reaches these gains with nearly 2x faster convergence in optimization steps, highlighting the effectiveness of structured self supervision in improving both performance and sample efficiency for VideoLLMs.
Knowing but Not Correcting: Routine Task Requests Suppress Factual Correction in LLMs
May 07, 2026LLMs reliably correct false claims when presented in isolation, yet when the same claims are embedded in task-oriented requests, they often comply rather than correct. We term this failure mode \emph{correction suppression} and construct a benchmark of 300 false premises to systematically evaluate it across eight models. Suppression rates range from 19\% to 90\%, with four models exceeding 80\%, establishing correction suppression as a prevalent and severe phenomenon. Mechanistic analysis reveals that suppression is not a knowledge failure: the model registers the error internally but task context diverts early-layer attention from the false claim as output intent crystallizes toward compliance at middle layers. We characterize this as \emph{knowing but not correcting} -- suppression occurs at response selection rather than knowledge encoding. Guided by this mechanism, we propose two training-free interventions. Correction Direction Steering (CDS) estimates a correction-compliance direction from matched pairs and injects it at middle layers before output intent crystallizes. Dynamic Payload Amplification (DPA) localizes payload tokens via attention divergence between early and late layers and amplifies their representation at the final layer, requiring no calibration data. Experiments on Qwen3.5-9B and LLaMA3.1-8B show both methods substantially improve factual strictness. CDS achieves the highest correction rate on Qwen3.5-9B (0\%$\to$58.2\%). DPA is the only method that preserves or improves reasoning capability on both models. These findings introduce \emph{factual strictness} -- the willingness to uphold accuracy against contextual pressures -- as a new dimension of model reliability.
Not Just What's There: Enabling CLIP to Comprehend Negated Visual Descriptions Without Fine-tuning
Feb 24, 2026Vision-Language Models (VLMs) like CLIP struggle to understand negation, often embedding affirmatives and negatives similarly (e.g., matching "no dog" with dog images). Existing methods refine negation understanding via fine-tuning CLIP's text encoder, risking overfitting. In this work, we propose CLIPGlasses, a plug-and-play framework that enhances CLIP's ability to comprehend negated visual descriptions. CLIPGlasses adopts a dual-stage design: a Lens module disentangles negated semantics from text embeddings, and a Frame module predicts context-aware repulsion strength, which is integrated into a modified similarity computation to penalize alignment with negated semantics, thereby reducing false positive matches. Experiments show that CLIP equipped with CLIPGlasses achieves competitive in-domain performance and outperforms state-of-the-art methods in cross-domain generalization. Its superiority is especially evident under low-resource conditions, indicating stronger robustness across domains.
WoVR: World Models as Reliable Simulators for Post-Training VLA Policies with RL
Feb 15, 2026Reinforcement learning (RL) promises to unlock capabilities beyond imitation learning for Vision-Language-Action (VLA) models, but its requirement for massive real-world interaction prevents direct deployment on physical robots. Recent work attempts to use learned world models as simulators for policy optimization, yet closed-loop imagined rollouts inevitably suffer from hallucination and long-horizon error accumulation. Such errors do not merely degrade visual fidelity; they corrupt the optimization signal, encouraging policies to exploit model inaccuracies rather than genuine task progress. We propose WoVR, a reliable world-model-based reinforcement learning framework for post-training VLA policies. Instead of assuming a faithful world model, WoVR explicitly regulates how RL interacts with imperfect imagined dynamics. It improves rollout stability through a controllable action-conditioned video world model, reshapes imagined interaction to reduce effective error depth via Keyframe-Initialized Rollouts, and maintains policy-simulator alignment through World Model-Policy co-evolution. Extensive experiments on LIBERO benchmarks and real-world robotic manipulation demonstrate that WoVR enables stable long-horizon imagined rollouts and effective policy optimization, improving average LIBERO success from 39.95% to 69.2% (+29.3 points) and real-robot success from 61.7% to 91.7% (+30.0 points). These results show that learned world models can serve as practical simulators for reinforcement learning when hallucination is explicitly controlled.
RLinf-USER: A Unified and Extensible System for Real-World Online Policy Learning in Embodied AI
Feb 08, 2026Online policy learning directly in the physical world is a promising yet challenging direction for embodied intelligence. Unlike simulation, real-world systems cannot be arbitrarily accelerated, cheaply reset, or massively replicated, which makes scalable data collection, heterogeneous deployment, and long-horizon effective training difficult. These challenges suggest that real-world policy learning is not only an algorithmic issue but fundamentally a systems problem. We present USER, a Unified and extensible SystEm for Real-world online policy learning. USER treats physical robots as first-class hardware resources alongside GPUs through a unified hardware abstraction layer, enabling automatic discovery, management, and scheduling of heterogeneous robots. To address cloud-edge communication, USER introduces an adaptive communication plane with tunneling-based networking, distributed data channels for traffic localization, and streaming-multiprocessor-aware weight synchronization to regulate GPU-side overhead. On top of this infrastructure, USER organizes learning as a fully asynchronous framework with a persistent, cache-aware buffer, enabling efficient long-horizon experiments with robust crash recovery and reuse of historical data. In addition, USER provides extensible abstractions for rewards, algorithms, and policies, supporting online imitation or reinforcement learning of CNN/MLP, generative policies, and large vision-language-action (VLA) models within a unified pipeline. Results in both simulation and the real world show that USER enables multi-robot coordination, heterogeneous manipulators, edge-cloud collaboration with large models, and long-running asynchronous training, offering a unified and extensible systems foundation for real-world online policy learning.
$π_\texttt{RL}$: Online RL Fine-tuning for Flow-based Vision-Language-Action Models
Oct 29, 2025


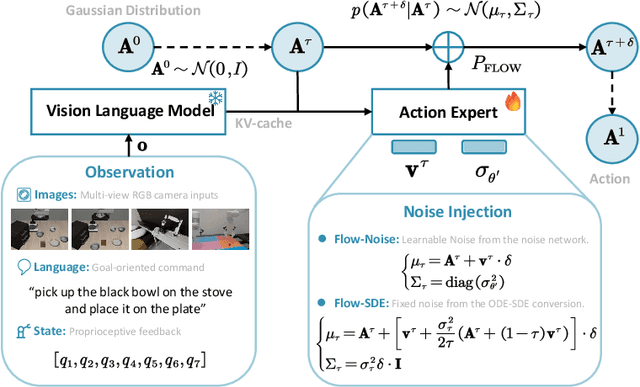
Vision-Language-Action (VLA) models enable robots to understand and perform complex tasks from multimodal input. Although recent work explores using reinforcement learning (RL) to automate the laborious data collection process in scaling supervised fine-tuning (SFT), applying large-scale RL to flow-based VLAs (e.g., $\pi_0$, $\pi_{0.5}$) remains challenging due to intractable action log-likelihoods from iterative denoising. We address this challenge with $\pi_{\text{RL}}$, an open-source framework for training flow-based VLAs in parallel simulation. $\pi_{\text{RL}}$ implements two RL algorithms: (1) {Flow-Noise} models the denoising process as a discrete-time MDP with a learnable noise network for exact log-likelihood computation. (2) {Flow-SDE} integrates denoising with agent-environment interaction, formulating a two-layer MDP that employs ODE-to-SDE conversion for efficient RL exploration. We evaluate $\pi_{\text{RL}}$ on LIBERO and ManiSkill benchmarks. On LIBERO, $\pi_{\text{RL}}$ boosts few-shot SFT models $\pi_0$ and $\pi_{0.5}$ from 57.6% to 97.6% and from 77.1% to 98.3%, respectively. In ManiSkill, we train $\pi_{\text{RL}}$ in 320 parallel environments, improving $\pi_0$ from 41.6% to 85.7% and $\pi_{0.5}$ from 40.0% to 84.8% across 4352 pick-and-place tasks, demonstrating scalable multitask RL under heterogeneous simulation. Overall, $\pi_{\text{RL}}$ achieves significant performance gains and stronger generalization over SFT-models, validating the effectiveness of online RL for flow-based VLAs.
RLinf: Flexible and Efficient Large-scale Reinforcement Learning via Macro-to-Micro Flow Transformation
Sep 19, 2025

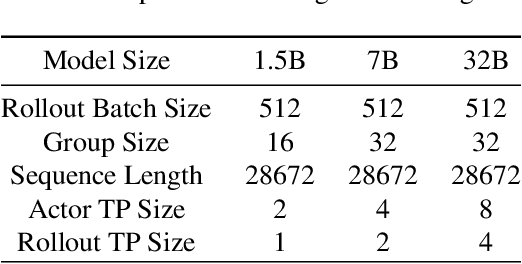
Reinforcement learning (RL) has demonstrated immense potential in advancing artificial general intelligence, agentic intelligence, and embodied intelligence. However, the inherent heterogeneity and dynamicity of RL workflows often lead to low hardware utilization and slow training on existing systems. In this paper, we present RLinf, a high-performance RL training system based on our key observation that the major roadblock to efficient RL training lies in system flexibility. To maximize flexibility and efficiency, RLinf is built atop a novel RL system design paradigm called macro-to-micro flow transformation (M2Flow), which automatically breaks down high-level, easy-to-compose RL workflows at both the temporal and spatial dimensions, and recomposes them into optimized execution flows. Supported by RLinf worker's adaptive communication capability, we devise context switching and elastic pipelining to realize M2Flow transformation, and a profiling-guided scheduling policy to generate optimal execution plans. Extensive evaluations on both reasoning RL and embodied RL tasks demonstrate that RLinf consistently outperforms state-of-the-art systems, achieving 1.1x-2.13x speedup in end-to-end training throughput.